
If you’ve ever shipped a project, celebrated the “launch,” and then quietly stopped checking results, you already know the punchline: activity is not impact. An evaluation framework with AI gives you a repeatable way to define success, measure it, and defend your decisions with evidence inside an AI Workspace and AI Whiteboard you can share with your team. And yes, it saves you from the “we feel like it worked” meeting.
Jeda.ai is used by 150,000+ users to turn messy inputs (docs, data, stakeholder notes) into editable visuals and decision-ready boards. Jeda.ai’s web search and multi-model setup can also help you pressure-test assumptions before you invest weeks in the wrong metric.
What is an evaluation framework
An evaluation framework is a structured plan that defines what you will evaluate, why it matters, how you will measure it, and how you will use the results. In public health, the CDC’s program evaluation framework is a widely cited example because it pairs evaluation steps with standards that keep the work useful, feasible, ethical, and accurate.
In practice, an evaluation framework answers six uncomfortable questions:
- What is the decision we’re trying to make?
- What does success look like, in numbers and in behavior?
- Which outcomes matter now, and which matter later?
- What data can we trust, and what data is missing?
- What is the evaluation method, and who owns it?
- What will we do if the results disagree with the plan?
A good framework also forces you to separate outputs (what you ship) from outcomes (what changes), and outcomes from impact (why it mattered).
Why use an evaluation framework with AI
Most teams skip evaluation because it is slow. Data is scattered. Stakeholders argue about definitions. The dashboard is “almost ready.” AI does not magically fix governance, but it can remove the friction that kills evaluation.
Here is what an evaluation framework with AI changes in real work:
- Faster metric alignment: AI drafts metric definitions, thresholds, and counter-metrics so the team debates substance, not wording.
- Better logic chains: AI turns goals into a clear outcomes map and flags missing links.
- Evidence-in workflows: AI can summarize documents, meeting notes, and customer feedback into measurable themes.
- Cohort clarity: AI suggests segmentation ideas (new users vs returning, regions, personas) so you do not average away the truth.
- Decision audit trail: Your AI Whiteboard becomes the record of why you picked a metric, why you ignored another, and what you learned.
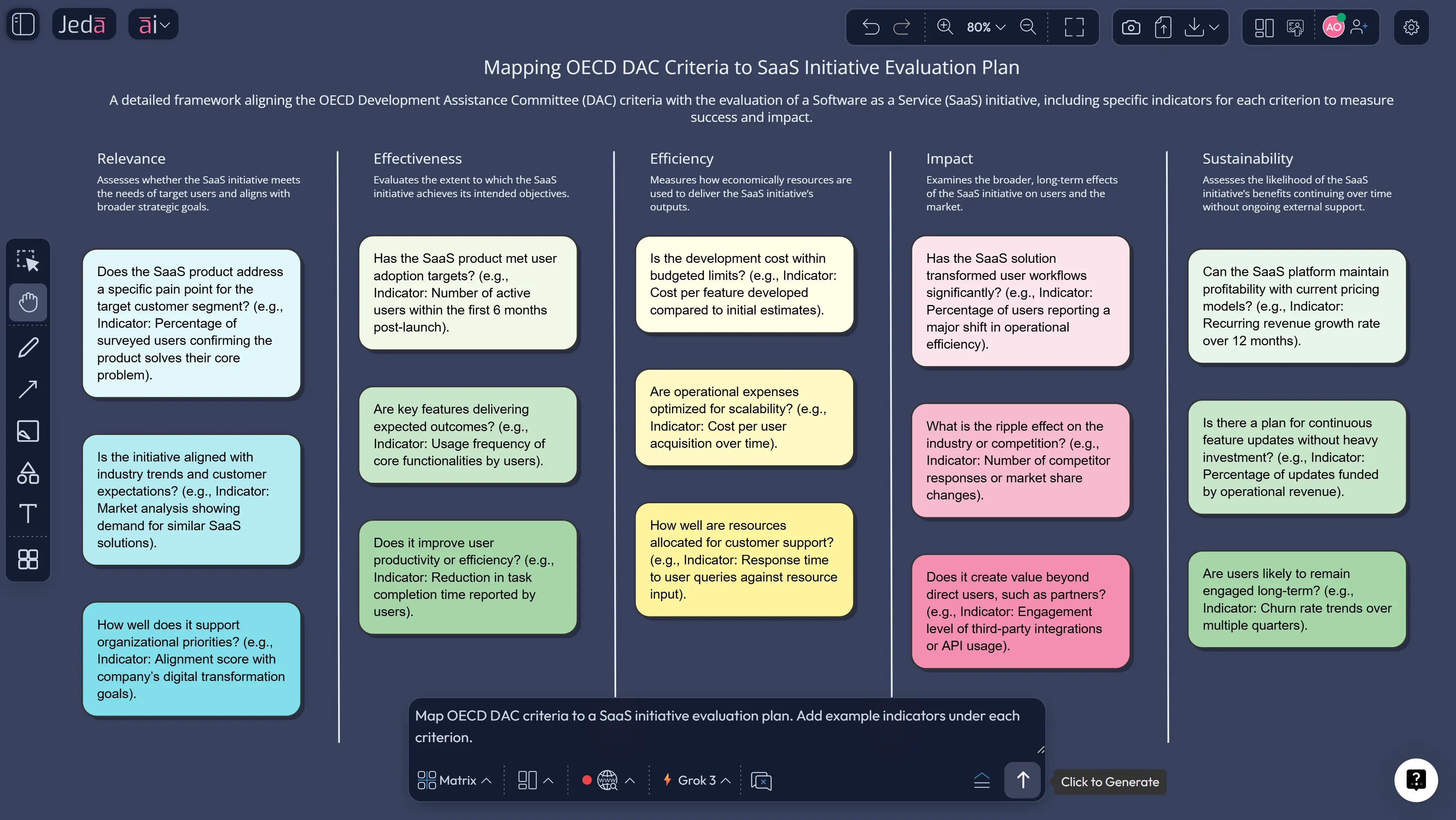
Evaluation also benefits from known criteria. The OECD DAC evaluation criteria (relevance, coherence, effectiveness, efficiency, impact, sustainability) are often used to structure judgments beyond raw KPI charts.
- Decision-first metrics
Start with the decision, then choose metrics. AI helps draft definitions, owners, and thresholds so the team can commit early.
- Evidence-in synthesis
Bring PDFs, notes, and transcripts into your AI Workspace. AI summarizes themes into measurable outcomes you can track.
- Repeatable evaluation cycles
Use one board per initiative. Reuse the same structure across launches so results are comparable quarter to quarter.
How to create an evaluation framework with AI in Jeda.ai
You can build an evaluation framework inside Jeda.ai using the Prompt Bar, then extend it with the AI+ button, and convert views with Vision Transform. Use the Matrix command when you want a structured grid (criteria, metrics, methods). Use Diagram when you want a causal map.
- Define the decision and scope
Open Jeda.ai, choose the Matrix command in the Prompt Bar, and write the decision you need to make. Add scope, timeframe, and who will use results.
- Draft outcomes and indicators
Ask for 3 layers: outputs, outcomes, impact. For each outcome, request 1 primary metric and 1 guardrail metric.
- Choose criteria and standards
Add a criteria row using OECD DAC or your internal criteria. Ask AI to map each metric to the criteria it supports.
- Pick methods and data sources
List data sources you already have. Ask AI to recommend methods: surveys, experiments, interviews, analytics, or document review.
- Assign owners and cadence
Add owners, update frequency, and a decision date. If the cadence is unclear, default to weekly during launch and monthly after.
- Extend and convert
Tap the AI+ button on any section to add detail. Use Vision Transform to convert the matrix into a flowchart or diagram when you need a narrative view.
Prompt you can copy
Use this in Jeda.ai’s Prompt Bar after selecting the Matrix command:
Build an evaluation framework for: [initiative].
Decision to support: [decision].
Timeframe: [dates].
Include sections: goals, outputs, outcomes, impact, primary metrics, guardrail metrics, data sources, methods, segmentation, risks, and decision rules.
Add OECD DAC criteria mapping.
Output as a clear matrix with owners and cadence.
Tip: run the same prompt with Jeda.ai’s Multi-LLM Agent (1–3 models) and let the aggregator pick the cleanest structure. You can also enable platform web search when you need domain benchmarks.
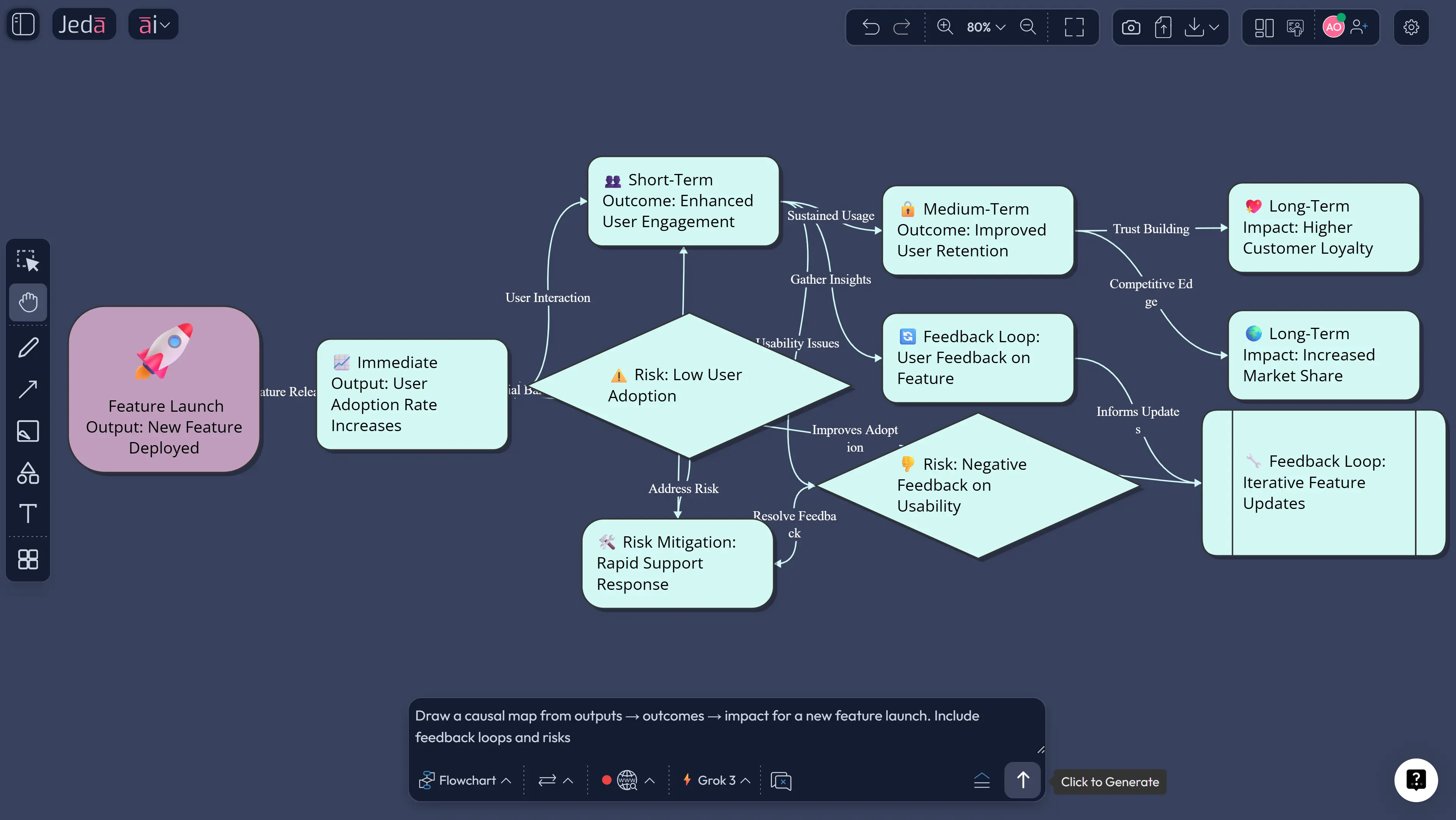
Example: evaluating a feature launch
Imagine you shipped “Team Workspaces” in a B2B SaaS product.
Bad evaluation question: “Did it increase engagement?”
Better evaluation question: “Did team workspaces increase multi-user adoption without raising support burden?”
A practical evaluation framework might include:
- Outcome: more accounts add a second active user within 14 days
- Metric: % of accounts with 2+ weekly active users (WAU)
- Guardrail: support tickets per active account
- Outcome: more repeat collaboration actions
- Metric: number of collaborative edits per account
- Guardrail: time-to-first-collaboration (should decrease)
- Impact: higher retention in the target segment
- Metric: 90-day retention for teams that created a workspace
- Guardrail: churn for non-team segment (should not spike)
Now you have a story that survives scrutiny, because each metric supports a decision.
Best practices and tips
Common mistakes to avoid
- Measuring what is easy, not what matters. Convenience metrics feel productive and mislead decisions.
- No baseline. If you cannot compare to “before,” the result is opinion.
- No counterfactual. If everything changed at once, you can’t attribute impact.
- No ownership. A metric without an owner becomes a ghost.
- Turning evaluation into performance theater. If negative results are punished, teams will hide them.
Frequently Asked Questions
- What is an evaluation framework with AI?
- An evaluation framework with AI is a structured plan for defining success, selecting metrics, and choosing methods, where AI helps draft the framework, map metrics to outcomes, and summarize evidence from documents and data into measurable indicators.
- Which evaluation criteria should I use?
- Use criteria that match your stakeholders. Many teams adopt OECD DAC criteria (relevance, coherence, effectiveness, efficiency, impact, sustainability) for structured judgment, then add product-specific criteria like usability, adoption, and risk.
- How do I pick the right metrics?
- Start from the decision. Choose one primary metric that directly reflects the desired outcome, then add one guardrail metric to catch side effects. Define the population, timeframe, and threshold before you collect data.
- Do I need experiments for every evaluation?
- No. Experiments are powerful when you need causal claims, but many evaluations use mixed methods: analytics trends, cohort comparisons, interviews, surveys, and document review. Pick the simplest method that supports the decision.
- How often should we review evaluation results?
- During launch, review weekly to catch early issues. After stabilization, move to monthly or quarterly. The cadence should match how quickly you can change the product or program based on findings.
- Can Jeda.ai export the evaluation framework?
- Yes. Jeda.ai exports boards as PNG, SVG, or PDF. If you need a slide deck, export an image or PDF and place it into your presentation tool.
- How does Jeda.ai help beyond a normal dashboard?
- Dashboards show numbers. Jeda.ai is an AI Workspace and AI Whiteboard where you also capture assumptions, criteria, evidence, and decision rules as editable visuals. That context is what makes evaluation reusable.
- What is the fastest way to start?
- Start with a single initiative and build one board: decision, outcomes, metrics, owners, cadence. Then use the AI+ button to extend sections and Vision Transform to create a narrative flowchart for stakeholders.
Sources and further reading
- [1]
Milstein, B. et al. (1999) . “Framework for Program Evaluation in Public Health” MMWR Recommendations and Reports (CDC).
View Source ↗ - [2]
Centers for Disease Control and Prevention (2024) . “About CDC's Program Evaluation Framework” CDC.
View Source ↗ - [3]
OECD Development Assistance Committee (DAC) (2019) . “Evaluation Criteria” OECD.
View Source ↗ - [4]
OECD DAC EvalNet (2019) . “Evaluation Criteria: Adapted Definitions and Principles for Use” OECD.
View Source ↗
Start Your Evaluation Framework with AI Today
Join over 150,000 professionals who use Jeda.ai to build decision-ready evaluation boards in one AI Workspace.
Try Free Template